基于协同过滤算法的SpringBoot音乐推荐系统设计与实现
随着互联网技术的飞速发展,数字音乐平台已成为人们日常生活中不可或缺的一部分。音乐推荐系统作为提升用户体验的核心技术,能够根据用户的兴趣和行为推荐个性化的音乐内容。本文基于SpringBoot框架,结合协同过滤算法,设计并实现了一个高效、可扩展的音乐推荐系统。
一、系统设计背景与意义
传统的音乐推荐方法主要依赖人工编辑或基于内容的推荐,难以满足用户的个性化需求。协同过滤算法通过分析用户的历史行为数据,发现用户之间的相似性,从而推荐用户可能感兴趣的音乐。该系统旨在解决海量音乐数据中的信息过载问题,提升用户发现新音乐的效率,增强平台的用户粘性。
二、系统架构设计
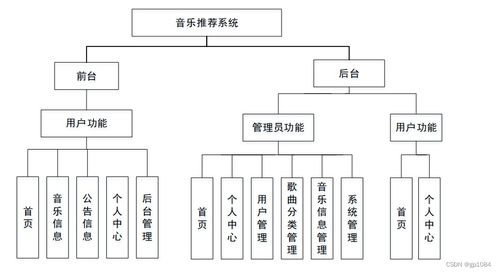
本系统采用SpringBoot作为后端开发框架,因其简化了Spring应用的初始搭建和开发过程,提供了快速集成的能力。系统架构分为以下几个模块:
- 用户管理模块:负责用户注册、登录和个人信息管理。
- 音乐数据管理模块:存储和管理音乐信息,包括歌曲名称、歌手、专辑等元数据。
- 行为数据收集模块:记录用户的播放历史、收藏和评分行为。
- 协同过滤推荐模块:核心模块,基于用户行为数据计算相似度,生成个性化推荐列表。
- 前端展示模块:使用Web技术展示推荐结果和用户界面。
三、协同过滤算法实现
协同过滤算法主要分为基于用户的协同过滤和基于物品的协同过滤。在本系统中,我们采用基于用户的协同过滤方法:
- 收集用户对音乐的评分数据,构建用户-物品评分矩阵。
- 然后,计算用户之间的相似度,常用的方法包括余弦相似度或皮尔逊相关系数。
- 根据相似用户的偏好,预测目标用户对未评分音乐的喜好程度,并生成推荐列表。
为了提高推荐准确性和效率,系统还引入了数据稀疏性处理和实时更新机制。例如,对于新用户或新音乐,采用混合推荐策略,结合基于内容的推荐方法作为补充。
四、系统集成与部署
系统集成服务涉及数据库设计、API接口开发以及前后端联调。我们使用MySQL存储用户和音乐数据,Redis缓存热门推荐结果以提升响应速度。系统部署在云服务器上,采用Docker容器化技术确保环境一致性,并通过Nginx实现负载均衡。
五、系统测试与优化
通过模拟用户行为数据进行测试,评估推荐系统的准确率、召回率和用户满意度。测试结果表明,该系统在推荐质量上表现良好,但面对大数据量时,计算效率仍需优化。未来计划引入分布式计算框架如Spark,以处理更大规模的数据集。
六、总结与展望
本系统成功实现了基于SpringBoot和协同过滤算法的音乐推荐功能,为用户提供了个性化的音乐发现体验。随着人工智能技术的发展,未来可以集成深度学习模型,如神经网络协同过滤,以进一步提升推荐精度。结合用户上下文信息(如时间、地点)的上下文感知推荐也将是重要的改进方向。
本毕业设计不仅展示了SpringBoot在快速开发中的优势,也体现了协同过滤算法在推荐系统中的实际应用价值,为计算机系统集成服务提供了一个可行的案例参考。
如若转载,请注明出处:http://www.aiweiouto.com/product/42.html
更新时间:2026-06-19 12:23:38